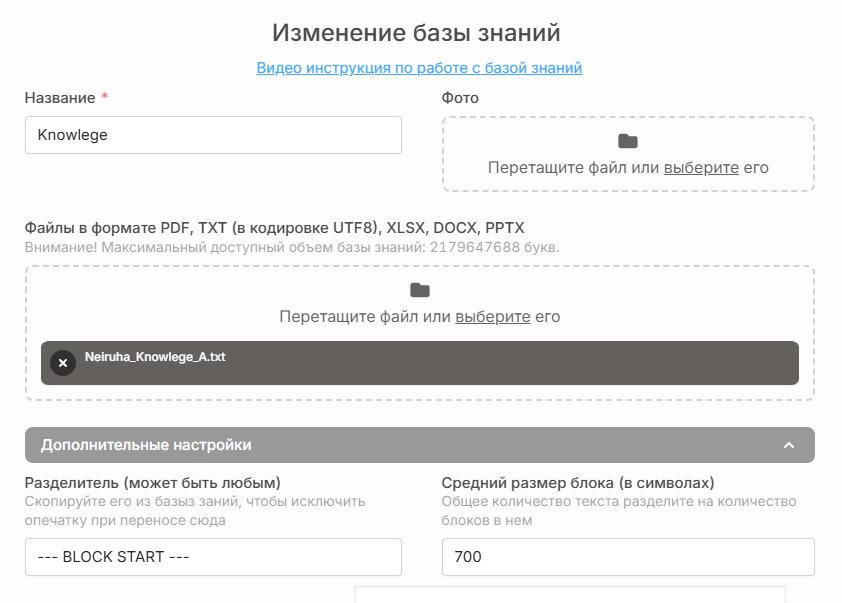
Что такое Embedding?
Embedding - это метод преобразования текстовой информации в числовые векторы, где семантически близкие понятия располагаются рядом в многомерном пространстве.
Как работает Embedding?
Текст разбивается на токены. Каждому токену присваивается векторное представление. Близкие по смыслу слова получают похожие векторные представления. При поиске система находит наиболее близкие по смыслу векторы. Преимущества:
Преимущества:
 Ограничения:
Ограничения:

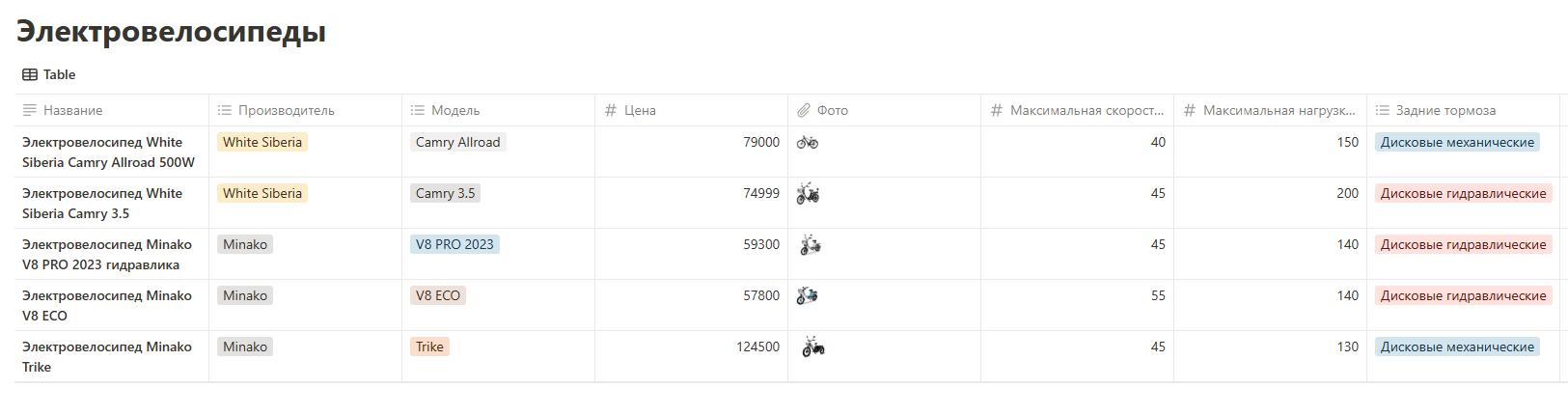
Для работы с базами данных в качестве знаний для ИИ агентов ProTalk можно использовать следующие функции: - №109 Получение данных из таблицы Airtable - №145 Чтение базы данных в Notion v.2 - №201 База данных в виде Google таблицы
- №109 Получение данных из таблицы Airtable - №145 Чтение базы данных в Notion v.2 - №201 База данных в виде Google таблицы




